前言:
為啥要做?這個某個小高三有關
從前從前我在推特上認識了一個小高一,我沒想過對方年紀這麼小
然後時不時的會聊天,聊一聊他就高三了
前陣子看到有個新聞說:有個爸爸做了一個九九乘法的Line bot給他的小孩用
我就想說:不然我來寫一個「高中考古題」的Line bot
實際實作之後發現,不太行,因為很多題目的「答案」都很長
就算使用了 shrink-to-fit 在按鈕上,字會變得很小難以閱讀
另外也嘗試過數學題,數學題嘛,應該答案都是些數字,結果不是
都是一堆數學符號,很難用單純的文字表現出來,所以也放棄了
完全放棄做考古題的Line bot之後,轉而往「英文單字」複習思考
因為只有單字,總不會有字太小的問題,也比較容易做⋯⋯
開始了
首先,先試著做個可以跑的Line bot出來看看,基本上就是上網查,入門完全參照30 天教你如何玩弄 Line bot API下去做,所以也全部以Node.js來寫,最初階的就是做echo bot
你輸入什麼,他就會回答什麼給你,這樣就完成第一步了,然後在開發階段都是使用ngrok這個好用的服務,Line官方文件也有提到,所以可以放心使用
然後是rich menu,這裡有個好用的網站,看不懂文字寫什麼沒關係,反正看著圖就會用了:LINE Rich Menu Maker,這邊是進入對話框後,下方會自動跳出來的menu,有幾個預設選項可以填寫
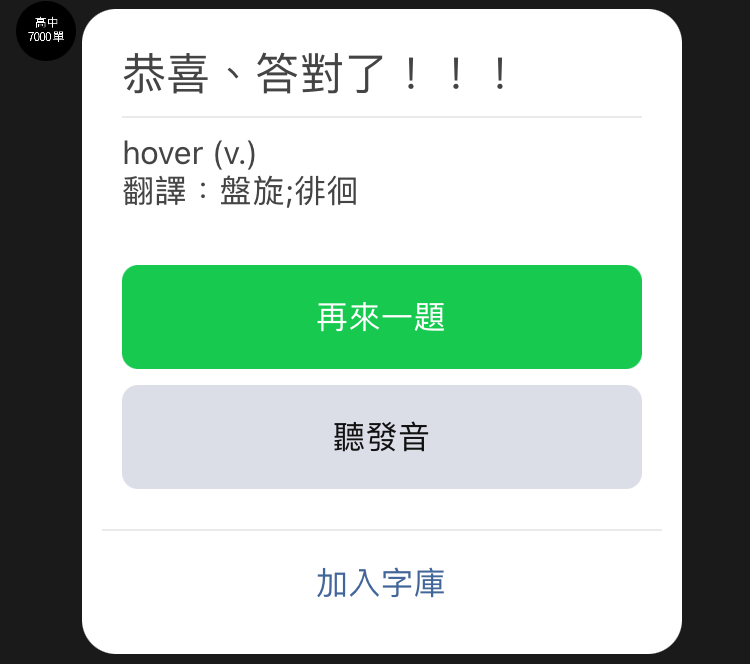
最開始的設計只有「開始測驗」跟「得分」,在後來的開發階段才出現「我的字庫」的想法,讓使用者可以複習自己不熟悉的單字

關於 Line API
在最初始的echo bot中,只有使用到一種Line API的資料傳輸方式,也就是「文字」,要取得使用者主動傳來的文字可以用event.message.text來擷取之後作出分析,像是上方rich menu的選單,三個項目就都是以純文字的形式來傳送指令,並作出相應的分析和反應
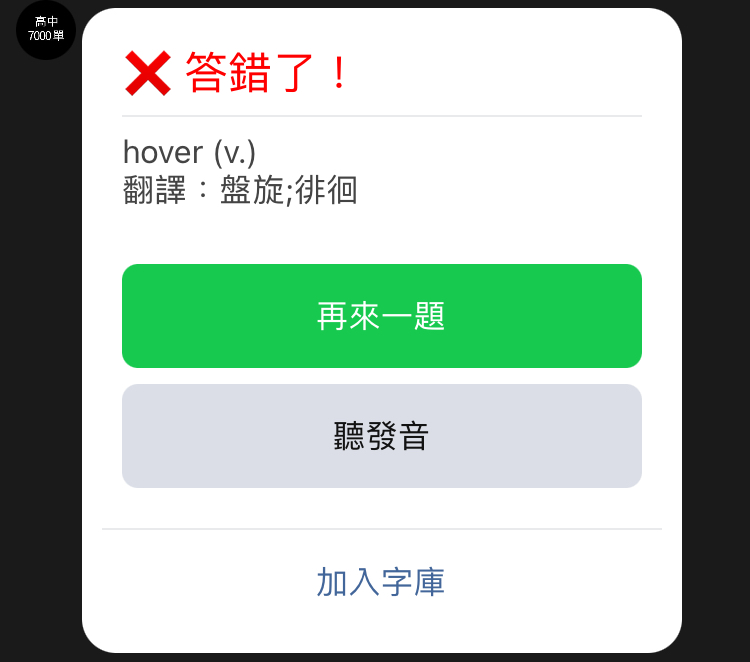
其次是postback,這會在接下來開始測驗之後大量使用在「按鈕」物件之上,並且可以隨之夾帶相應的參數回傳,像是當使用者按下題目的答案之一時,就是使用postback來回傳該答案的id,後台取得資料後比對是否與正確答案相符合,再回應出是否正確答案的回應
 |
 |
 |
字庫來源
本Line bot使用的7000單字彙來源下載自:【Excel教學】如何解析高中7000單字表,使用regex解析後為如下格式:
{
"word": "able (adj.)",
"translate": "能;有能力的"
},
...
之後使用以下程式碼批次加上ID:
const fs = require('fs');
const words = require('./words.json');
function addId(id) {
return function iter(o) {
if ('word' in o) {
o.id = id++;
}
Object.keys(o).forEach(function (k) {
Array.isArray(o[k]) && o[k].forEach(iter);
});
};
}
words.forEach(addId(1))
fs.writeFile('./words.json', JSON.stringify(words), function (error, data) {
if (error) throw error;
});
項目即變為:
{
"word": "able (adj.)",
"translate": "能;有能力的",
"id": 1
},
...
關於出題模式
在出題的時候會有五種出題方式:「英文出題」、「中文出題」、「發音出題」、「英文出題 (高階)」、「中文出題 (高階)」
其中所謂「高階」,實際上在原有的單字庫中就有分為一到六級,我將其中的第五和第六等級的單字提取出來作為高階題庫,而一般的出題方式則是所有單字都有機會考到,沒有做區隔。
發音出題是最後開發階段,小高三提出的想法,聽發音然後填單字。這個feature一度有點難倒我,因為我知道九九乘法那個bot的案例,他是用額外跳出頁面填寫答案來達成這件事。但是後來我思考了一下,發現可以直接用簡單的方式做到:首先每次出題要在/user_question資料夾下建立該user的題目json檔案,然後當有純文字訊息進來時,檢查是否存在該檔案,如果存在就判斷是否為正確答案,如此一來就不需要額外跳出網頁了。
關於我的字庫
「我的字庫」是用來瀏覽在測驗中儲存的不熟悉單字,點擊之後會列出使用者儲存的所有單字,但是礙於Line API的限制(carousel最多只能10頁),目前單字量儲存的上限是70個單字。點擊列表中單字的「查看」按鈕,就可以查詢該單字的詳細解釋和翻譯,翻譯來源來自天火字典(本Line bot為免費提供所有需要的用戶使用,如有侵權請來信告知),包含了音標、翻譯、例句、詞態等等。
 |
 |
關於發音
在每次答題後,會出現「聽發音」的按鈕;在我的字庫進入查看後也有相同的按鈕,目前的音訊來源是從天火字典下載,部分有缺漏的單字則是從Sound of Text網站下載。由於音訊品質上的要求,之後會改用@google-cloud/text-to-speech來批次下載音訊,重新製作。
目前Line API僅接受m4a檔案格式,且須為連結形式,所以需要加入以下程式碼才能存取/audio資料夾:
app.use('/audio/', express.static('./audio/'));
Line API的音訊message的回覆格式範例如下
{
"type": "audio",
"originalContentUrl": "https://words7000.unlink.men/audio/1.m4a",
"duration": 1000
}
關於發音出題
由於Line API單次replay token只能回覆一則訊息,所以發音出題無法以「音訊+文字」的方式來表現,後來找出的方式是以flex訊息混合「影片+文字」的方式出題,範例如下:
{
"type": "flex",
"altText": "考試開始,不要作弊!",
"contents": {
"type": "bubble",
"hero": {
"type": "video",
"url": "https://words7000.unlink.men/video/1.mp4",
"previewUrl": "https://words7000.unlink.men/audio/cover.png",
"altContent": {
"type": "image",
"url": "https://words7000.unlink.men/audio/cover.png",
"flex": 1,
"size": "full",
"aspectRatio": "16:9",
"aspectMode": "cover"
},
"action": {
"type": "uri",
"label": "action",
"uri": "https://words7000.unlink.men/video/1.mp4"
},
"aspectRatio": "16:9"
},
"body": {
"type": "box",
"layout": "vertical",
"contents": [
{
"type": "text",
"wrap": true,
"text": "請點擊影片聽取音檔\n並輸入答案後送出"
}
]
}
}
}
之後在訊息接收的地方,在switch default 的地方進一部分作出判斷:
function handleMessageEvent(event) {
switch (event.message.text) {
...
default:
let user = event.source.userId;
let path = __dirname + `/user_question/${user}.json`;
if (fs.existsSync(path)) {
return handleAudioAnswer(event);
}
else {
return client.replyMessage(event.replyToken, echo);
}
}
}
將音訊轉為影片檔的部分使用的fluent-ffmpeg,程式碼如下:
const ffmpeg = require('fluent-ffmpeg');
const command = ffmpeg();
const temp_words = require('./words.json');
for (let i = 0; i < temp_words.length; i++) {
(function (x) {
setTimeout(function() {
ffmpeg()
.addInput(`./audio/cover.png`)
.addInput(`./audio/${temp_words[x].id}.m4a`)
.inputFormat('mp4')
.save(`./video/${temp_words[x].id}.mp4`);
}, 500 * x)
})(i);
}
由於合成出來的影片發現不能用,事後又用轉檔軟體轉了一次才成功在Line上播放,但是因為影片播放在Line跳出訊息時是靜音的,所以使用者每次都需要點開來聽取才行,說實在有點麻煩。
結語
以上大致就是我開發過程中的經歷,在擷取和處理字典內容、以及下載音檔、轉換影片上花了比較多時間,其餘部分則都參照Line官方的document依序照著做就能完成,不算是太困難的專案,專案內容開源放在GitHub上:zenkarsha/words7000